
ConflictScore: Measuring How Language Models Handle Conflicting Evidence
Published:
TL;DR: Existing “factuality/faithfulness” metrics usually ask: is the answer supported by the evidence?
ConflictScore asks a sharper question: what if the evidence set itself disagrees—and the model acts overconfident anyway?
We introduce a claim-level metric (CS-C, CS-R), a benchmark (ConflictBench), and show conflict-aware regeneration improves truthfulness on TruthfulQA.
Why conflicts in evidence matter (and why current metrics miss them)
Modern LLM systems increasingly answer questions with retrieved documents (RAG), but retrieval often brings back disagreeing sources: different timestamps, interpretations, and opinions. In these settings, a response can look “supported” under standard metrics even if half the documents contradict it.
ConflictScore is built for exactly this situation: when support and contradiction coexist in the grounding set, we measure whether the model acknowledges that conflict—or confidently picks a side.

What is ConflictScore?
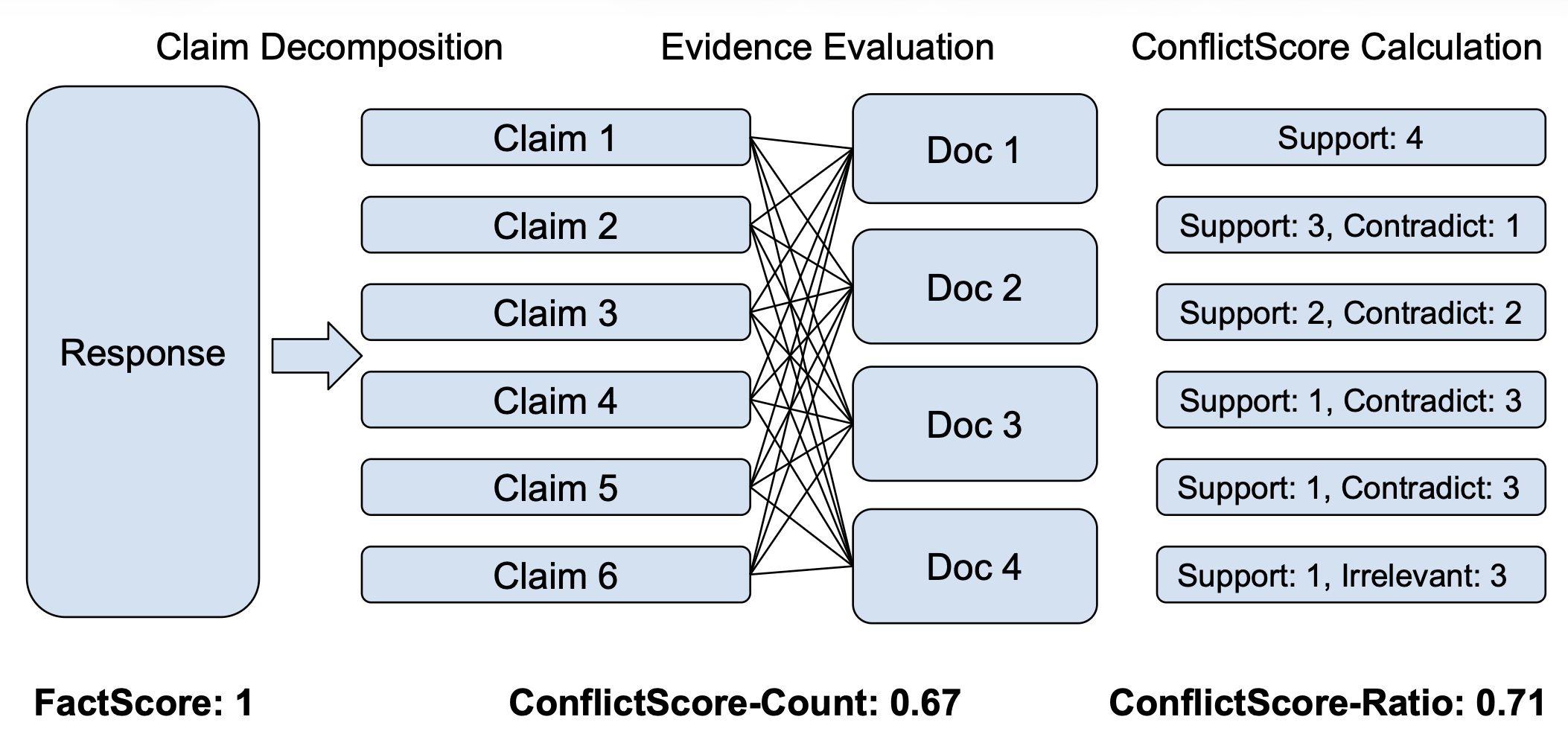
ConflictScore evaluates a model response in three stages:
- Claim decomposition: split the response into atomic claims.
- Evidence evaluation: for each claim and each document, predict a relation:
- SUPPORTS, CONTRADICTS, or IRRELEVANT
- Aggregate conflicts into two complementary scores:
- CS-C (ConflictScore-Count): fraction of claims that have both supporting and contradicting documents.
- CS-R (ConflictScore-Ratio): for each claim, compute
[ \frac{|D^-|}{|D^+| + |D^-|} ] and average across claims. (Higher = more contradiction pressure.)
Lower is better: fewer conflicted claims, or weaker contradiction.
A concrete example: “supported” doesn’t mean “safe”
Many existing metrics effectively treat evidence as a single pool: if any document supports a claim, the claim is marked supported—even if other documents contradict it.
ConflictScore keeps documents separate, so it can flag claims that are simultaneously supported and contradicted.
Faithfulness is not enough when the evidence is inconsistent. Conflict awareness is a distinct skill.
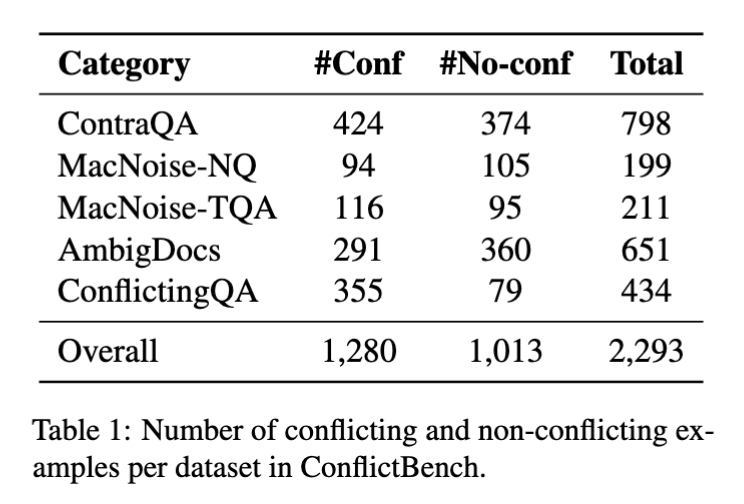
ConflictBench: a unified benchmark for conflict detection
To systematically evaluate conflict detection, we introduce ConflictBench, a unified dataset spanning multiple conflict types:
- Ambiguity / underspecification (AmbigDocs)
- Counterfactual / adversarial contradictions (ContraQA, MacNoise)
- Naturally contentious questions & opinions (ConflictingQA)
Dataset statistics
How well does ConflictScore detect conflicts?
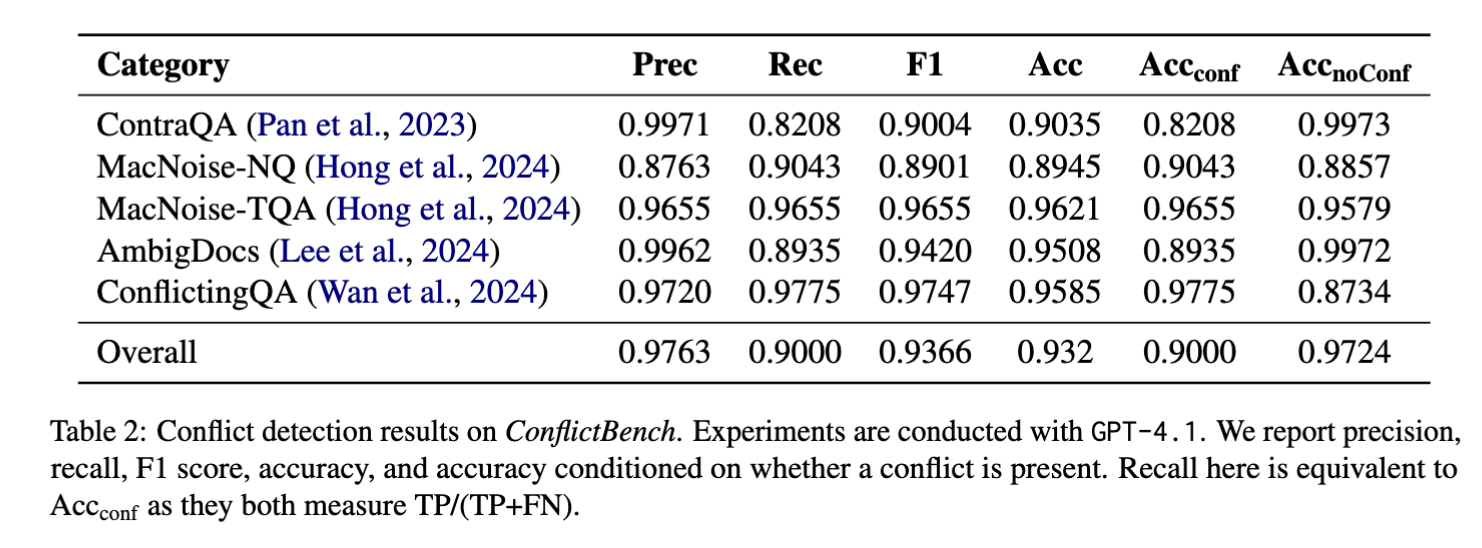
We evaluate the conflict-detection subtask:
Given a claim + grounding documents, predict Conflict vs No Conflict
(Conflict = at least one SUPPORTS and at least one CONTRADICTS in the set)
Main results (conflict detection)
Where it fails: local inconsistency inside a single document
Some errors come from documents that contradict themselves (e.g., early paragraphs suggest X, conclusion denies X). That can confuse claim–document labeling.

Benchmarking frontier LLMs: prompting helps… but only a bit
We benchmark multiple models under three prompting strategies:
- RAG: write a report from documents (no special instruction).
- RAG (Balanced): mild instruction to hedge / consider perspectives.
- RAG (Super-Balanced): strong, rule-based balanced reporting instruction.
Results
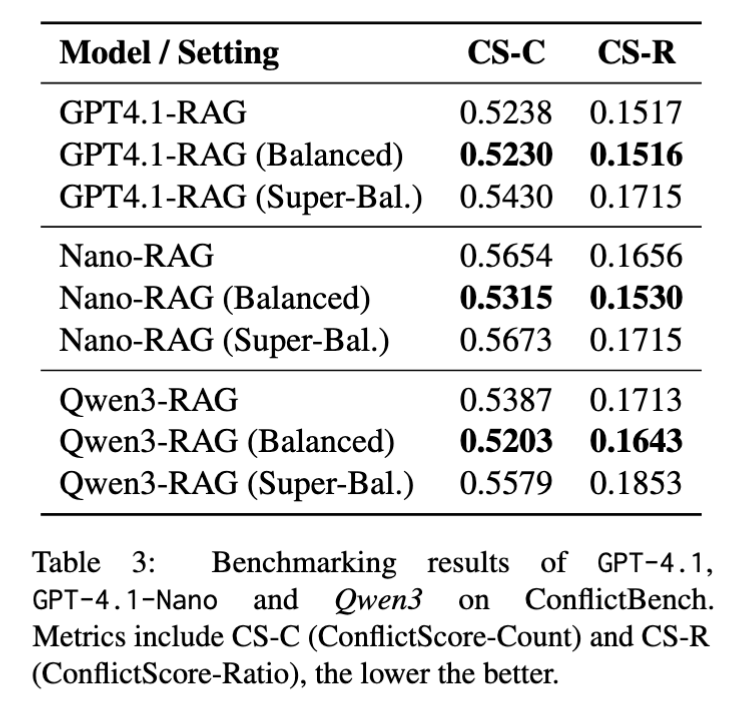
Key takeaway: even when explicitly told to hedge, models often still “collapse” to a single stance in the presence of contradictory sources.
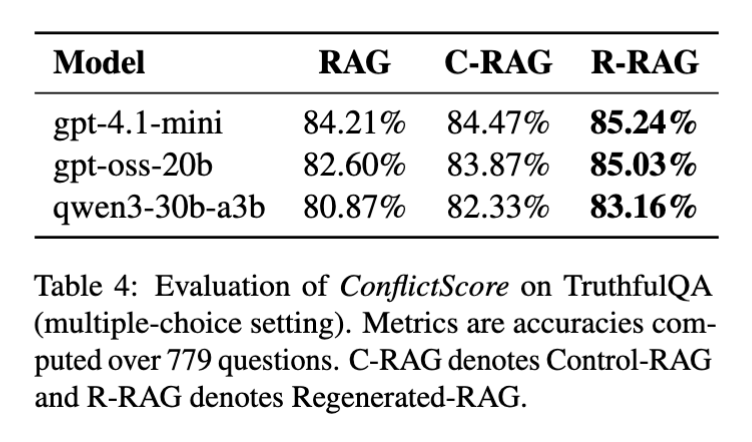
Using ConflictScore as a corrective signal: improving TruthfulQA
ConflictScore isn’t just diagnostic: we also use it as feedback to improve answers.
We compare:
- RAG: answer with retrieved docs
- Control-RAG: stronger cautionary instructions (no ConflictScore)
- Regenerated-RAG (R-RAG): generate → run ConflictScore → feed back conflict signal → regenerate
Multiple-choice TruthfulQA results
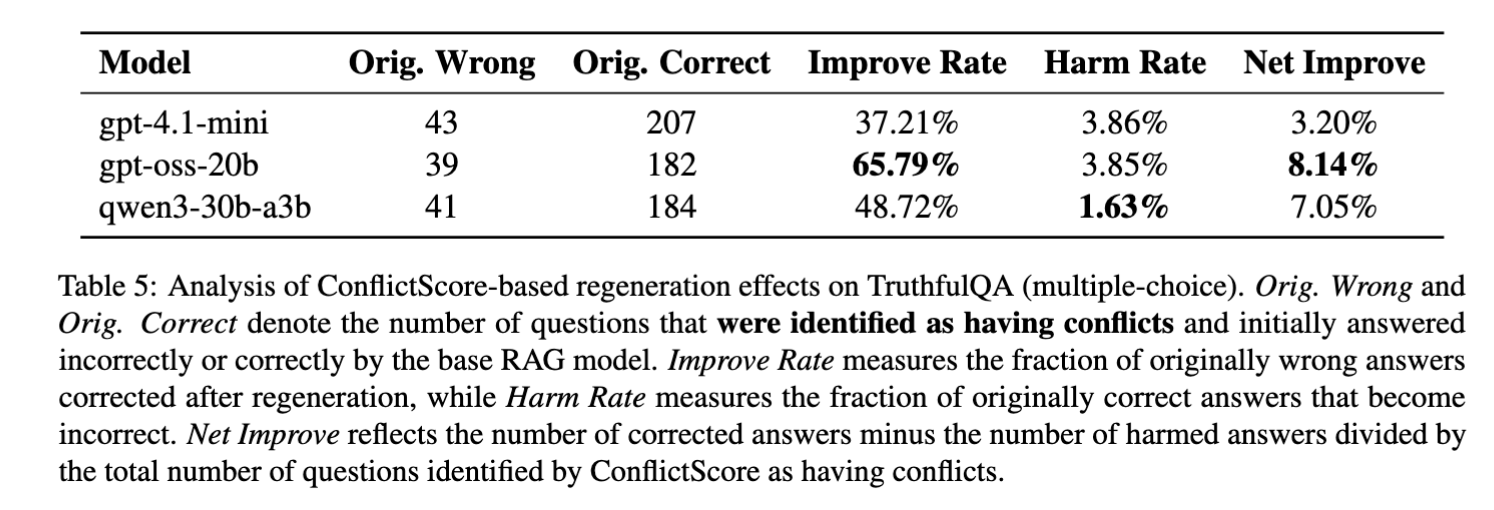
Why regeneration works: it fixes wrong answers more than it breaks right ones

How to use ConflictScore in practice
When ConflictScore is most useful
- RAG systems answering from heterogeneous web sources
- Domains with time drift (numbers, rankings, policies)
- Topics with persistent disagreement (health guidance, social policy, product claims)
What to report alongside ConflictScore
- CS-C (how many claims are conflicted)
- CS-R (how severe the contradiction balance is)
- (Optional) a conflict breakdown by claim type or section (intro vs conclusion)
Limitations and what’s next
- Cost: claim-by-document checking can be expensive for long outputs and large retrieval sets.
- Local inconsistency: some “conflicts” are inside a single document rather than across documents.
- Reliability weighting: models can be swayed by many low-quality sources; future work could integrate source credibility and recency.